Secara umum terdapat beberapa Ukuran Penyebaran Data, namun kali ini kita akan fokus pada tiga yang utama:
- Range (Jangkauan)
- Variance (Varians)
- Standard Deviation (Simpangan Baku)
Kita akan menggunakan data dummy yang sama seperti sebelumnya untuk menghitungnya:
Data Awal Nilai Kepuasan:
| Partisipan | Nilai Kepuasan |
|---|---|
| 0 | 72 |
| 1 | 13 |
| 2 | 67 |
| 3 | 11 |
| 4 | 71 |
| 5 | 18 |
| 6 | 43 |
| 7 | 32 |
| 8 | 60 |
| 9 | 87 |
| 10 | 51 |
| 11 | 13 |
| 14 | 49 |
| 17 | 78 |
Untuk mempermudah analisis, kita akan menggunakan data “Nilai Kepuasan” yang telah diurutkan dari yang terkecil hingga terbesar, seperti yang digunakan pada contoh sebelumnya:
$$11,14,15,22,25,38,39,45,58,59,61,61,64,65,67,68,79,81,86,87$$
Total data (n)=20 & Mean ($\bar{x}$)=52.25.
1. Range (Jangkauan)
Range adalah selisih antara nilai terbesar dan nilai terkecil dalam kumpulan data. Ini adalah ukuran penyebaran yang paling sederhana.
Rumus Range
$$Range = \text{Nilai Maksimum} − \text{Nilai Minimum}$$
Perhitungan: Dari data terurut: Nilai Maksimum =87 Nilai Minimum =11
Range = 87−11
Range = 76
R Code
# data
nilai_kepuasan <- c(11, 14, 15, 22, 25, 38, 39, 45, 58, 59, 61, 61, 64, 65, 67, 68, 79, 81, 86, 87)
range_nilai <- max(nilai_kepuasan) - min(nilai_kepuasan)
print(paste("Range dari data tersebut sebesar:", range_nilai))
Output:
[1] "Range dari data tersebut sebesar: 76"
2. Variance (Varians)
Varians adalah rata-rata dari kuadrat selisih setiap nilai data dengan mean. Varians mengukur seberapa jauh setiap angka dalam set data dari mean (rata-rata), dan dengan demikian dari setiap angka lainnya dalam set.
Rumus Varians (untuk sampel)
$$s^2= \frac{\sum^n_{i=1} (x_i − \bar{x})^2}{n-1}$$
Dimana:
$s^2$ = Varians sampel $x_i$ = Nilai data ke-i $\bar{x}$ = Mean sampel $n$ = Jumlah data
Perhitungan:
Mean ($\bar{x}$)=52.25 $n$ = 20
Pertama, hitung $(x_i−\bar{x})^2$ untuk setiap nilai:
$(11−52.25)^2=(−41.25)^2=1701.5625$
$(14−52.25)^2=(−38.25)2=1463.0625$
$(15−52.25)^2=(−37.25)^2=1387.5625$
$(22−52.25)^2=(−30.25)^2=915.0625$
$(25−52.25)^2=(−27.25)^2=742.5625$
$(38−52.25)^2=(−14.25)^2=203.0625$
$(39−52.25)^2=(−13.25)^2=175.5625$
$(45−52.25)^2=(−7.25)^2=52.5625$
$(58−52.25)^2=(5.75)^2=33.0625$
$(59−52.25)^2=(6.75)^2=45.5625$
$(61−52.25)^2=(8.75)^2=76.5625$
$(61−52.25)^2=(8.75)^2=76.5625$
$(64−52.25)^2=(11.75)^2=138.0625$
$(65−52.25)^2=(12.75)^2=162.5625$
$(67−52.25)^2=(14.75)^2=217.5625$
$(68−52.25)^2=(15.75)^2=248.0625$
$(79−52.25)^2=(26.75)^2=715.5625$
$(81−52.25)^2=(28.75)^2=826.5625$
$(86−52.25)^2=(33.75)^2=1139.0625$
$(87−52.25)^2=(34.75)^2=1207.5625$
Jumlah dari semua $(x_i−\bar{x})^2$:
$$\sum(x_i − \bar{x})^2 = 1701.5625+1463.0625+...+1207.5625 = 9524.75$$
Varians (s2):
$s^2 = \frac{9524.75}{20 − 1} = \frac{9524.75}{19}$ $s^2 = 501.3026$
R Code
varians_nilai <- var(nilai_kepuasan)
print(paste("Varians dari data tersebut sebesar:", varians_nilai))
Output:
[1] "Varians dari data tersebut sebesar: 501.302631578947"
3. Standard Deviation (Simpangan Baku)
Standar deviasi adalah akar kuadrat dari varians. Ini adalah ukuran seberapa tersebarnya nilai-nilai dalam kumpulan data relatif terhadap mean. Standar deviasi dinyatakan dalam unit yang sama dengan data asli, membuatnya lebih mudah diinterpretasikan daripada varians.
Rumus Standar Deviasi (untuk sampel):
$$s = \sqrt{s^2}= \sqrt{\frac{\sum^n_{i=11}(x_i-\bar{x})^2}{n-1}}$$
Dimana:
s = Standar deviasi sampel $s^2$ = Varians sampel
Perhitungan: Dari perhitungan varians sebelumnya:
$s^2 = 501.3026$
Standar Deviasi (s): $s = \sqrt{501.3026}$ $s = 22.39$
R Code:
std_dev_nilai <- sd(nilai_kepuasan)
print(paste("Standar Deviasi dari data tersebut sebesar:", std_dev_nilai))
Output:
[1] "Standar Deviasi dari data tersebut sebesar: 22.3897885559038"
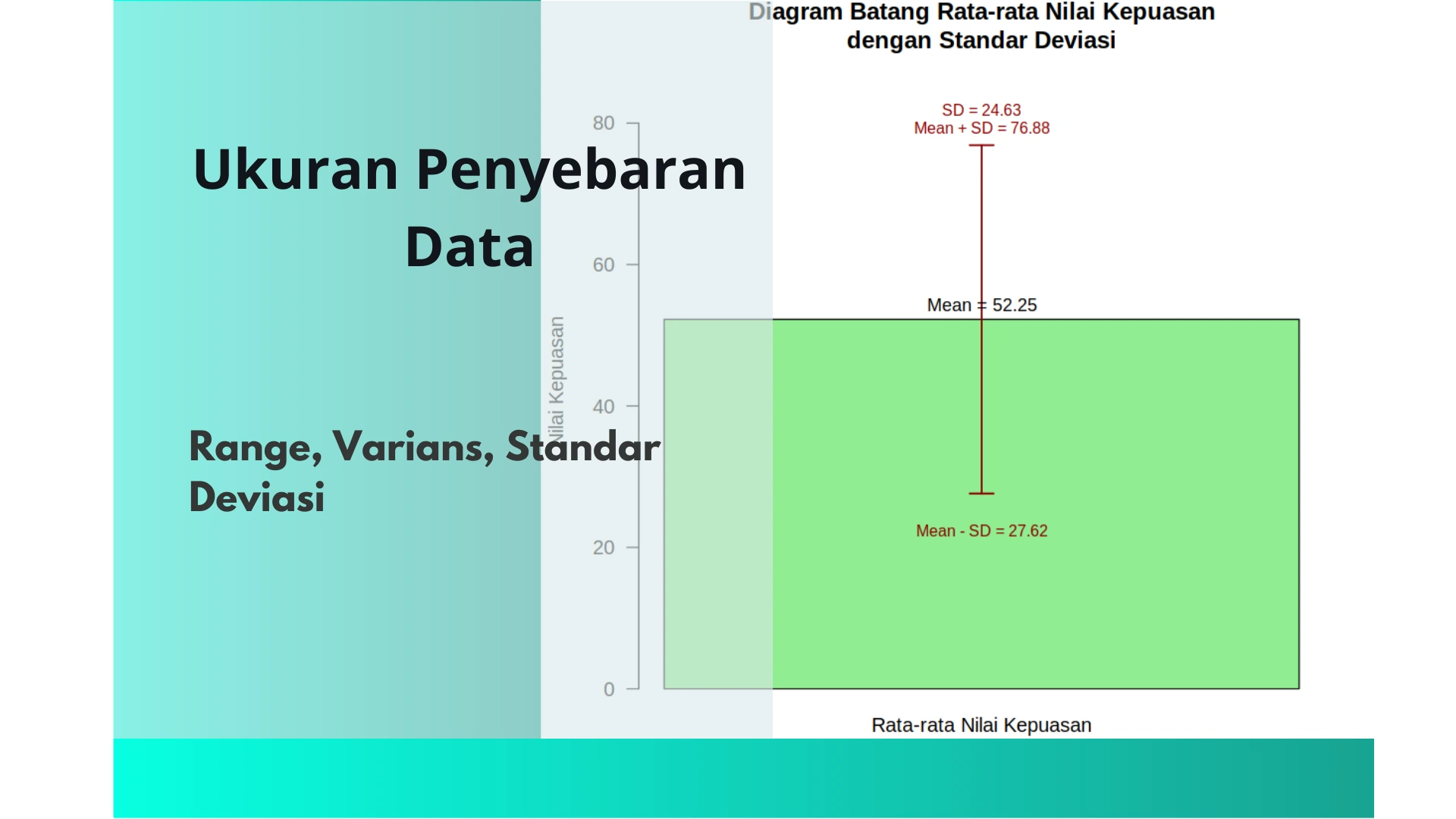
Visualiasi Standart Deviasi
# 1. Hitung Mean dan Standar Deviasi
mean_nilai <- mean(nilai_kepuasan)
sd_nilai <- sd(nilai_kepuasan)
# Tampilkan nilai mean dan sd untuk referensi
print(paste("Mean Nilai Kepuasan:", round(mean_nilai, 2)))
print(paste("Standar Deviasi Nilai Kepuasan:", round(sd_nilai, 2)))
# 2. Persiapan untuk plotting
bar_label <- "Rata-rata Nilai Kepuasan"
# 3. Membuat Bar Chart dengan Error Bar untuk Standar Deviasi
bar_centers <- barplot(height = mean_nilai,
names.arg = bar_label,
ylim = c(0, mean_nilai + sd_nilai + 10),
main = "Diagram Batang Rata-rata Nilai Kepuasan\ndengan Standar Deviasi",
ylab = "Nilai Kepuasan",
xlab = "",
col = "lightgreen",
las = 1)
# Menambahkan error bar
arrows(x0 = bar_centers,
y0 = mean_nilai - sd_nilai,
x1 = bar_centers,
y1 = mean_nilai + sd_nilai,
angle = 90,
code = 3,
length = 0.1,
lwd = 1.5,
col = "darkred")
# Menambahkan teks
text(x = bar_centers, y = mean_nilai + 2, labels = paste("Mean =", round(mean_nilai, 2)), col = "black", cex = 0.9)
text(x = bar_centers, y = mean_nilai + sd_nilai + 5, labels = paste("SD =", round(sd_nilai, 2)), col = "darkred", cex = 0.8)
text(x = bar_centers, y = mean_nilai - sd_nilai - 3, labels = paste("Mean - SD =", round(mean_nilai - sd_nilai, 2)), col = "darkred", cex = 0.8, pos = 1)
text(x = bar_centers, y = mean_nilai + sd_nilai + 0, labels = paste("Mean + SD =", round(mean_nilai + sd_nilai, 2)), col = "darkred", cex = 0.8, pos = 3)
/2.webp)
Kesimpulan
Range itu jarak antara nilai paling kecil dan paling besar. Jadi, misalnya kamu punya angka 2, 5, dan 9, maka range-nya 9 - 2 = 7.
Varians itu seperti ngukur seberapa beda-beda angka dari rata-ratanya. Tapi caranya agak unik: beda-beda itu dihitung pakai kuadrat (dikali dirinya sendiri). Kalau variansnya kecil, berarti angkanya mirip-mirip semua, gak beda jauh
Kalau Standar Deviasi (SD) makin kecil, misalnya mendekati 1 atau bahkan 0, itu artinya data kamu makin rapi atau mirip-mirip. Jadi, semakin kecil SD, hasilnya makin bisa dipercaya atau valid. Bayangin kamu dan teman-temanmu semua dapat nilai ulangan hampir sama, misalnya 80, 81, 79. Nah, SD-nya kecil. Itu bagus, karena nilainya nggak jauh beda—artinya pengukuran atau penilaiannya konsisten.