
Kepopulerannya terus meningkat hingga Jumbo berhasil mencetak rekor penonton, bahkan digadang-gadang mampu mengalahkan pendapatan animasi Frozen. Ini menjadi tonggak penting bagi industri animasi lokal, menunjukkan bahwa karya anak bangsa bisa bersaing di kancah global dengan karakter yang kuat, cerita yang relevan, dan kualitas produksi yang tidak kalah dari buatan luar negeri.
Kontroversi di Balik Popularitas
Dengan banyaknya pandangan positif terkait animasi ini, pada tanggal sekian Wakil Presiden Gibran menyampaikan pendapatnya mengenai munculnya era baru animasi Indonesia di YouTube. Pernyataan tersebut disampaikan dalam sebuah unggahan yang bertujuan untuk mengapresiasi kemajuan industri kreatif tanah air. Namun, unggahan tersebut justru menuai beragam respons dari netizen. Banyak yang memberikan kritik tajam dan menilai pernyataan tersebut terlalu dibesar-besarkan. Tak sedikit pula yang menekan tombol dislike di YouTube, menandakan adanya perbedaan pandangan publik terhadap klaim tersebut.
Meskipun sempat menuai kritik atas pernyataannya mengenai era baru animasi Indonesia di YouTube, Wakil Presiden Gibran Rakabuming Raka tetap menunjukkan dukungannya terhadap karya anak bangsa. Pada Jumat, 11 April 2025, Gibran mengajak 139 anak yatim dari empat panti asuhan di Jakarta untuk menonton film animasi lokal berjudul Jumbo di Senayan City, Jakarta Pusat .
Analisis Sentimen
Di sini, kita akan mencoba menganalisis 1.000 komentar dari Twitter yang menjadi sampel terkait animasi Jumbo. Sampel ini dikumpulkan dari tanggal 31 Maret 2025 — bertepatan dengan hari pertama penayangan animasi tersebut — hingga saat ini. Komentar-komentar tersebut mencerminkan berbagai sudut pandang masyarakat, mulai dari dukungan terhadap karya anak bangsa hingga kritik terhadap promosi dan ekspektasi yang dibangun di sekitarnya.
Dataset lengkap dapat Anda unduh melalui tautan berikut: Jumbo Dataset.
Persiapan Awal: Impor Pustaka dan Unduh Modul
Langkah pertama adalah mengimpor semua pustaka Python yang kita butuhkan untuk analisis ini. Ini mencakup pustaka untuk manipulasi data (Pandas, NumPy), pemrosesan teks (re, NLTK, Sastrawi), analisis sentimen (TextBlob), visualisasi (Matplotlib), dan pembuatan word cloud (WordCloud). Kita juga perlu mengunduh beberapa modul NLTK (stopwords, punkt) yang diperlukan untuk pemrosesan teks Bahasa Indonesia.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import re
import Sastrawi
from Sastrawi.StopWordRemover.StopWordRemoverFactory import StopWordRemoverFactory, StopWordRemover, ArrayDictionary
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
import torch
from wordcloud import WordCloud, STOPWORDS
from nltk.util import bigrams
from nltk.corpus import stopwords
from collections import Counter
import nltk
from nltk.util import trigrams
from nltk.corpus import stopwords
from collections import Counter
nltk.download('stopwords')
nltk.download('punkt_tab')
nltk.download('punkt')
Memuat Data Komentar
Setelah pustaka siap, kita muat dataset komentar Twitter mentah dari file CSV (serial_jumbo.csv) ke dalam sebuah DataFrame Pandas untuk diproses lebih lanjut.
df = pd.read_csv('serial_jumbo.csv')
df.head()
Memilih Kolom Teks dan Merapikan Index
Untuk fokus pada analisis teks, kita buat salinan DataFrame dan hanya pilih kolom full_text yang berisi komentar. Kita juga melakukan reset_index() agar penomoran baris menjadi standar (0, 1, 2, …).
df1 = df.copy()
df1 = df1["full_text"].reset_index()
Pembersihan Teks Tahap 1: Regex
Teks dari media sosial seringkali mengandung noise. Kita definisikan fungsi clean_text menggunakan regular expression (regex) untuk membersihkan teks dari:
Username (@mention) Hashtag (#topic) Indikator Retweet (‘RT ‘) URL (http/https) Karakter selain huruf, angka, dan spasi Spasi berlebih Fungsi ini diterapkan untuk membuat kolom baru text_clean.
def clean_text(text):
text = re.sub(r'@[A-Za-z0-9]+', '', text)
text = re.sub(r'#\w+', '', text)
text = re.sub(r'RT[\s]+', '', text)
text = re.sub(r'https?://\S+', '', text)
text = re.sub(r'[^A-Za-z0-9 ]', '', text)
text = re.sub(r'\s+', ' ', text).strip()
return text
df1['text_clean'] = df1["full_text"].apply(clean_text)
df1
Pembersihan Teks Tahap 2: Konversi ke Huruf Kecil
Untuk menyeragamkan teks dan memastikan kata seperti “Bagus” dan “bagus” dianggap sama, kita konversi semua isi kolom text_clean menjadi huruf kecil (lowercase).
df1["text_clean"] = df1["text_clean"].str.lower()
df1.head()

Pembersihan Teks Tahap 3: Penghapusan Stopword (Sastrawi)
Kata-kata umum dalam Bahasa Indonesia seperti ‘yang’, ‘di’, ‘ke’, ‘dari’, ‘ini’, ‘itu’ (disebut stopwords) sering muncul namun kurang memberikan makna sentimen. Kita gunakan library Sastrawi yang spesifik untuk Bahasa Indonesia untuk menghapus stopwords ini dari kolom text_clean.
import Sastrawi
from Sastrawi.StopWordRemover.StopWordRemoverFactory import StopWordRemoverFactory, StopWordRemover, ArrayDictionary
# more_stop_words = ["tidak"]
stop_words = StopWordRemoverFactory().get_stop_words()
# stop_words.extend(more_stop_words)
new_array = ArrayDictionary(stop_words)
stop_words_remover_new = StopWordRemover(new_array)
def stopword(str_text):
str_text = stop_words_remover_new.remove(str_text)
return str_text
df1["text_clean"] = df1["text_clean"].apply(lambda x: stopword(x))
df1.head()

Checkpoint 1: Simpan Hasil Pembersihan Awal
Untuk menyimpan progres setelah langkah-langkah pembersihan awal (regex, lowercase, stopword removal), kita simpan DataFrame df1 ke sebuah file CSV baru. Ini berguna agar kita tidak perlu mengulang proses dari awal jika terjadi error di langkah selanjutnya.
df1.to_csv("abbriviation.csv")
Normalisasi Teks: Penggantian Singkatan/Slang
Bahasa dalam cuitan Twitter seringkali tidak baku dan menggunakan banyak singkatan atau slang. Kita definisikan sebuah kamus (abbreviation_dict) yang berisi pasangan singkatan dan bentuk bakunya. Kemudian, kita buat fungsi replace_abbreviations untuk mengganti setiap singkatan dalam teks dengan bentuk bakunya berdasarkan kamus tersebut. Hasilnya disimpan dalam kolom baru text_clean_abbr.
# clear coloumn
pd.set_option('display.max_colwidth', None)
df2 = df1.copy()
abbreviation_dict = {
"yg": "yang",
"tdk": "tidak",
"gk": "nggak",
"ga": "nggak",
"dlm": "dalam",
"sdh": "sudah",
"blm": "belum",
"tp": "tapi",
"krn": "karena",
"dr": "dari",
"utk": "untuk",
"dgn": "dengan",
"aja": "saja",
"gokillll": "gokil",
"gak": "tidak",
"bgt": "banget",
"anak2nya": "anak anaknya",
"bg": "bang",
"inj": "in journey",
"getol": "berusaha keras",
"emak2": "emak-emak",
"tgk": "tengok",
"ni": "ini",
"dooo": "dong",
"kyknya": "kayaknya",
"knp": "kenapa",
"jd": "jadi",
"q1": "kuartal 1",
"q2": "kuartal 2",
"btw": "by the way",
"soksokan": "sok-sokan",
"pke": "pakai",
"nobar": "nonton bareng",
"ttg": "tentang",
"fomo": "fear of missing out",
"pansos": "pencitraan sosial",
"id": "indonesia",
"ri":"republik indonesia",
"gt" : "gitu",
"apaa":"apa",
"sma" : "sama",
"bhkn" : "bahkan",
"nntn" : "nonton",
"bsok" : "besok",
"moga" : "semoga",
"jg" : "juga",
"sblm" : "sebelum",
"mengagung2kan" : "mengagung agungkan",
"bener2" : "benar benar",
"samaaaaa" : "sama",
"tntg" : "tentang",
"ny" : "nya",
"tiba2" : "tiba tiba",
"gw" : "saya",
"aku" : "saya",
"rp": "rupiah",
"jadi": "menjadi",
"raup": "meraih",
"horor2nya": "horor horornya",
"trsss": "terus",
"cuihhhhhhhh": "cuih",
"film2" : "film film",
"dompet10" : "dompet",
"lg" : "lagi",
"masingmasing" : "masing masing",
"bgtttt" : "banget",
"gada": "tidak ada",
"gapapa": "nggak apa-apa",
"kalo": "kalau",
"dapet": "dapat",
"acuh": "cuek",
"misuh2": "misuh-misuh",
"bagusss" : "bagus",
"au": "tidak tahu",
"lho": "loh",
"ampe" : "sampai",
"udh" : "udah",
"ngmg": "ngomong",
"bgtt" : "banget",
"janji2an" : "janji janjian",
"kelar2" : "kelar kelar",
"amp" : "sampai",
"kenapaaaaaaaaa" : "kenapa",
"bangettt" : "banget",
"anak2" : "anak anak",
"ttp" : "tetap",
"emg" : "memang",
"anakanak": "anak anak",
"baca2" : "baca baca",
"novel2" : "novel novel",
"gara2" : "gara gara",
"gituu" : "gitu",
"srg" :"sering",
"aelah": "alah",
"lakilaki":"laki laki",
"bro": "bang",
"teruuuusssssss" : "terus",
"se": "sangat",
"coy": "cuy",
"bgs" : "bagus",
"gaada" : "tidak ada",
"bkn" : "bukan",
"buzzerbuzzer" : "buzzer buzzer",
"fenomena2" : "fenomena fenomena",
"gembor2": "gembar-gembor",
"nimbrung": "ikut campur",
"nggak": "tidak",
"blokk": "blok",
"plssss" : "please",
"pliss" : "please",
"bukn" : "bukan",
"wapres" : "wakil presiden",
"cmn" : "hanya",
"tpi" : "tapi",
"b ajaa" : "biasa aja",
"bejir" : "astaga",
"masing2" : "masing masing",
"ofj": "oke fine juga",
"wamen": "wakil menteri",
"wamenekraf": "wakil menteri ekonomi kreatif",
"bs": "bisa",
"gpp": "nggak apa-apa",
"ig": "Instagram",
"filmanimasi": "film animasi",
"bs": "bisa",
"bgt": "banget",
"memng" : "memang",
"syg" : "sayang",
"gtu" : "gitu",
"byk" : "banyak",
"cth" : "contoh",
"sia2" : "sia sia",
"berkalikali" : "berkalikali",
"berkali kali" : "berkalikali",
"Bcs" : "Because",
"sy" : "saya",
"sok-sokan" : "soksokan",
"kl" : "jika"
}
def replace_abbreviations(text):
words = text.split()
words = [abbreviation_dict[word] if word in abbreviation_dict else word for word in words]
return ' '.join(words)
df2['text_clean_abbr'] = df2['text_clean'].apply(replace_abbreviations)
df2['text_clean_abbr']
Tokenisasi Teks
Tokenisasi adalah proses memecah kalimat atau teks menjadi unit-unit kata atau simbol individual yang disebut token. Ini adalah langkah penting sebelum melakukan stemming atau analisis n-gram. Kita akan melakukan tokenisasi pada kolom text_clean (teks yang sudah dibersihkan dari stopwords, namun sebelum penggantian singkatan - perhatikan ini mungkin perlu disesuaikan jika stemming lebih baik dilakukan setelah normalisasi singkatan).
tokenized = df2["text_clean"].apply(lambda x:x.split())
tokenized

Stemming Teks (Sastrawi)
Stemming adalah proses mengubah kata ke bentuk dasarnya (kata dasar) dengan menghapus imbuhan. Misalnya, ‘menganalisis’, ‘dianalisis’ akan diubah menjadi ‘analisis’. Kita gunakan kembali library Sastrawi untuk melakukan stemming pada daftar token yang sudah kita buat. Hasil stemming akan digabungkan kembali menjadi string per komentar.
from Sastrawi.Stemmer.StemmerFactory import StemmerFactory
def stemming(text_cleaning):
factory = StemmerFactory()
stemmer = factory.create_stemmer()
do = []
for w in text_cleaning:
dt = stemmer.stem(w)
do.append(dt)
d_clean = []
d_clean = " ".join(do)
# print(d_clean)
return d_clean
tokenized = tokenized.apply(stemming)
Checkpoint 2: Simpan Hasil Stemming
Kita simpan lagi hasil pemrosesan teks yang kini sudah melalui tahap stemming ke file CSV. Ini akan menjadi input untuk tahap translasi dan analisis sentimen.
tokenized.to_csv("Data Animasi Jumbo/tokenized.csv",index=False)
Memuat Data Hasil Stemming
Muat kembali data yang sudah bersih dan di-stemming dari file CSV yang baru saja disimpan. Data ini siap untuk diterjemahkan.
data = pd.read_csv("Data Animasi Jumbo/tokenized.csv")
data.head()

Translasi Teks ke Bahasa Inggris
Library analisis sentimen TextBlob bekerja paling baik dengan teks Bahasa Inggris. Oleh karena itu, kita perlu menerjemahkan kolom teks Bahasa Indonesia (yang sudah di-stemming, text_stemmed) ke Bahasa Inggris. Kita gunakan library googletrans (perlu koneksi internet) dan definisikan fungsi translate_with_googletrans yang juga menyertakan penanganan error jika translasi gagal untuk suatu teks. Hasil terjemahan disimpan di kolom tweet_english.
from googletrans import Translator
def translate_with_googletrans(tweet):
if not isinstance(tweet, str) or not tweet.strip():
return None
translator = Translator()
try:
translation_result = translator.translate(tweet, src='id', dest='en')
return translation_result.text
except Exception as e:
print(f"Error translating: {str(tweet)[:50]}... - Error: {e}")
return None
if "text_clean" in data.columns:
data["tweet_english"] = data["text_clean"].apply(translate_with_googletrans)
else:
print("Error: Kolom 'text_clean' tidak ditemukan di DataFrame.")
Checkpoint 3: Simpan Hasil Translasi
Simpan kembali DataFrame yang kini sudah berisi kolom terjemahan Bahasa Inggris (tweet_english) ke dalam file CSV. Ini adalah data final yang siap untuk dianalisis sentimennya.
data.to_csv("translate.csv")
Memuat Data Hasil Translasi
Muat data final yang berisi semua kolom hasil pemrosesan, termasuk teks asli, teks bersih (stemmed), dan teks terjemahan Bahasa Inggris, untuk melakukan analisis sentimen.
data = pd.read_csv("translate.csv")
data.tail()
data.to_csv("translate.csv")
Analisis Sentimen Menggunakan Model RoBERTa dari CardiffNLP
Pada bagian ini, kita akan melakukan analisis sentimen terhadap komentar yang telah dikumpulkan dan diterjemahkan ke dalam Bahasa Inggris. Berbeda dengan pendekatan sebelumnya yang mungkin menggunakan TextBlob, kali ini kita akan memanfaatkan model transformer yang lebih canggih, yaitu cardiffnlp/twitter-roberta-base-sentiment. Model ini dilatih khusus untuk tugas analisis sentimen pada teks dari media sosial seperti Twitter, sehingga diharapkan dapat memberikan hasil yang lebih akurat dan kontekstual.
Pertama, kita akan memuat tokenizer dan model dari Hugging Face Transformers library. Kemudian, kita membuat sebuah pipeline untuk analisis sentimen yang memudahkan kita dalam memproses teks.
# Load model dan tokenizer dari CardiffNLP
model_name = "cardiffnlp/twitter-roberta-base-sentiment"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# Buat pipeline sentiment
sentiment_pipeline = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer, return_all_scores=False)
# Lakukan analisis sentimen
results = sentiment_pipeline(data["tweet_english"].tolist())
data["sentiment"] = [r['label'] for r in results]
# Tampilkan data
data

Setelah mendapatkan hasil dari pipeline, label sentimen yang dihasilkan oleh model (misalnya, LABEL_0, LABEL_1, LABEL_2) perlu kita petakan ke kategori yang lebih mudah dipahami seperti ‘Negatif’, ‘Netral’, dan ‘Positif’. Hasil pemetaan ini kemudian akan kita tambahkan sebagai kolom baru bernama sentiment ke dalam DataFrame data kita.
label_map = {
"LABEL_0": "Negative",
"LABEL_1": "Neutral",
"LABEL_2": "Positive"
}
data["sentiment"] = [label_map[r['label']] for r in results]
data.sentiment.value_counts()
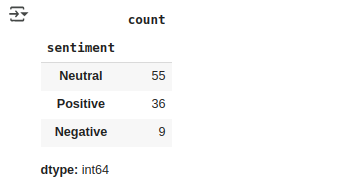
Memfilter Data Positif
Untuk menganalisis lebih spesifik kata-kata atau frasa yang sering muncul dalam komentar bernada positif, kita perlu memfilter DataFrame data dan membuat DataFrame baru (data_positif) yang hanya berisi baris dengan nilai ‘Positif’ pada kolom klasifikasi.
data_positif = data[data["klasifikasi"] == "Positif"]
data_negatif = data[data["sentiment"] == "Negative"]
Analisis Bigram pada Sentimen Negatif
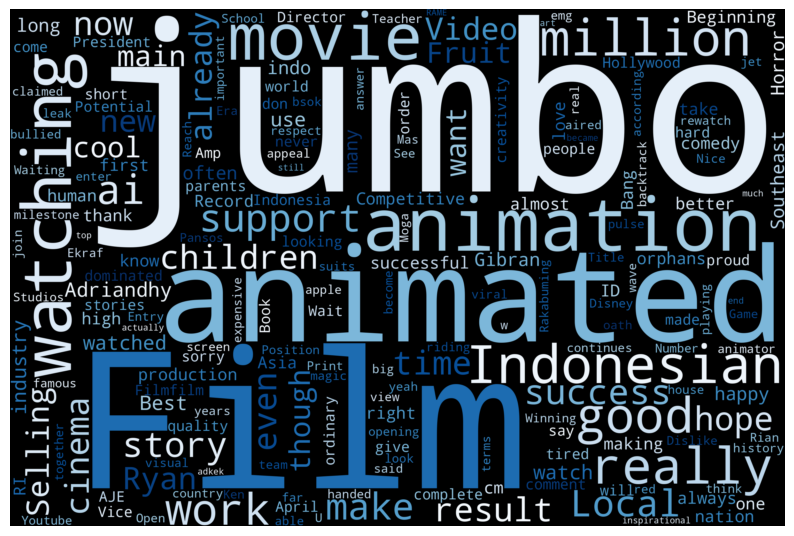
Kata individual kadang kurang memberikan konteks. Analisis bigram (pasangan dua kata yang muncul berurutan) dapat memberikan wawasan lebih baik. Kita akan mengekstrak bigram dari teks komentar positif (data_positif[’text_stemmed’] atau kolom teks relevan lainnya), menghitung frekuensinya, dan memvisualisasikannya dalam bentuk Word Cloud. Kali ini kita gunakan stopwords Bahasa Indonesia dari NLTK untuk filtering yang lebih tepat.
# Fungsi untuk menampilkan word cloud
def plot_cloud(wordcloud):
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
all_words = ' '.join([tweets for tweets in data['tweet_english']])
# Membuat objek WordCloud dengan konfigurasi tertentu
wordcloud = WordCloud(
width=3000,
height=2000,
random_state=3,
background_color='black',
colormap='Blues_r',
collocations=False,
stopwords=STOPWORDS
).generate(all_words)
plot_cloud(wordcloud)
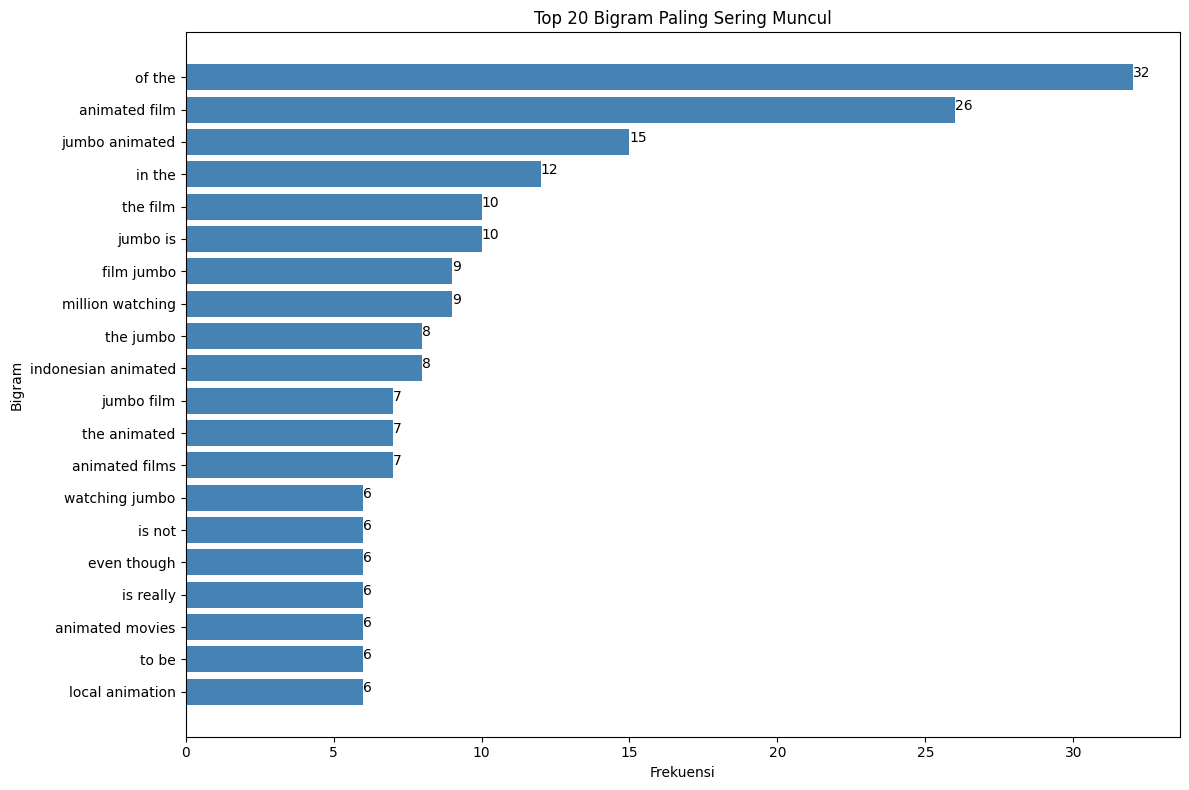
Visualisasi Top N Bigram Positif (Bar Chart)
Untuk melihat secara eksplisit bigram mana yang paling dominan dalam sentimen positif dan membandingkan frekuensinya, kita buat bar chart horizontal yang menampilkan N (misal, 20) bigram teratas berdasarkan frekuensi kemunculannya.
nltk.download('stopwords')
nltk.download('punkt_tab')
def plot_cloud(wordcloud):
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
language = 'indonesian' # Ganti jika teks dalam bahasa lain, misal 'english'
try:
stop_words = set(stopwords.words(language))
except IOError:
stop_words = set()
all_tokens_filtered = []
# Asumsi: 'data' adalah DataFrame dan 'text_clean' kolom teksnya
for text in data['tweet_english']:
if isinstance(text, str):
tokens = nltk.word_tokenize(text.lower())
filtered = [word for word in tokens if word.isalnum() and word not in stop_words and len(word) > 1]
all_tokens_filtered.extend(filtered)
if len(all_tokens_filtered) > 1:
bigram_list = list(bigrams(all_tokens_filtered))
formatted_bigrams = [" ".join(bigram) for bigram in bigram_list]
bigram_counts = Counter(formatted_bigrams)
wordcloud = WordCloud(
width=3000,
height=2000,
random_state=3,
background_color='black',
colormap='Blues_r'
)
if bigram_counts:
wordcloud.generate_from_frequencies(bigram_counts)
plot_cloud(wordcloud)

if 'bigram_counts' in locals() and bigram_counts:
N = 20
top_bigrams = bigram_counts.most_common(N)
if top_bigrams:
labels = [item[0] for item in top_bigrams]
counts = [item[1] for item in top_bigrams]
labels.reverse()
counts.reverse()
plt.figure(figsize=(12, 8))
plt.barh(labels, counts, color='steelblue')
plt.title(f'Top {N} Bigram Paling Sering Muncul')
plt.xlabel('Frekuensi')
plt.ylabel('Bigram')
for index, value in enumerate(counts):
plt.text(value, index, str(value))
plt.tight_layout()
plt.show()
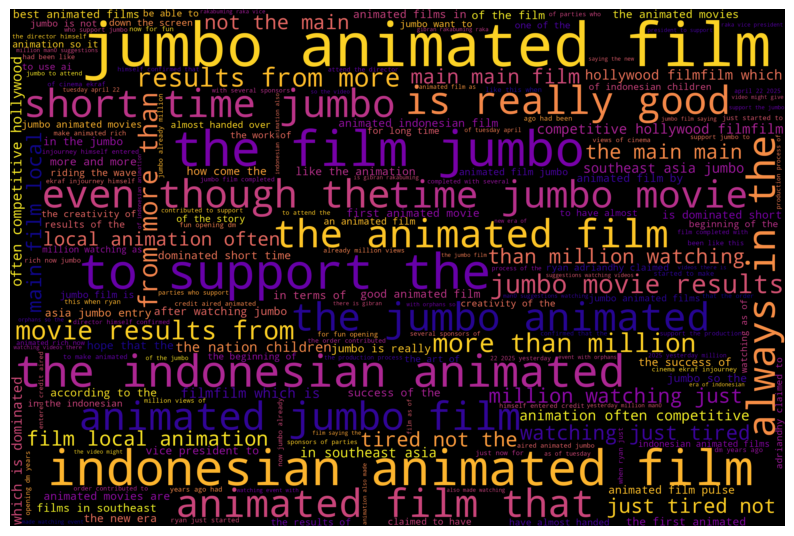
Analisis Trigram Keseluruhan
Kita perluas analisis n-gram dengan melihat trigram (rangkaian tiga kata berurutan) dari keseluruhan dataset (bukan hanya positif). Ini dapat menangkap frasa atau konteks yang lebih panjang. Prosesnya mirip dengan analisis bigram: tokenisasi, filtering stopwords, pembuatan trigram, perhitungan frekuensi, dan visualisasi menggunakan Word Cloud serta bar chart horizontal untuk Top N trigram.
def plot_cloud(wordcloud):
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
# --- Perhitungan Trigram ---
language = 'indonesian' # Sesuaikan jika perlu
try:
stop_words = set(stopwords.words(language))
except IOError:
stop_words = set()
all_tokens_filtered = []
# Asumsi 'data' adalah DataFrame dan 'text_clean' adalah kolom teks
for text in data['tweet_english']:
if isinstance(text, str):
tokens = nltk.word_tokenize(text.lower())
filtered = [word for word in tokens if word.isalnum() and word not in stop_words and len(word) > 1]
all_tokens_filtered.extend(filtered)
trigram_counts = Counter()
if len(all_tokens_filtered) > 2:
trigram_list = list(trigrams(all_tokens_filtered))
formatted_trigrams = [" ".join(trigram) for trigram in trigram_list]
trigram_counts = Counter(formatted_trigrams)
# --- Word Cloud dari Trigram ---
if trigram_counts:
wordcloud = WordCloud(
width=3000,
height=2000,
random_state=3,
background_color='black',
colormap='plasma'
)
wordcloud.generate_from_frequencies(trigram_counts)
plot_cloud(wordcloud)
if trigram_counts:
N = 20
top_trigrams = trigram_counts.most_common(N)
if top_trigrams:
labels = [item[0] for item in top_trigrams]
counts = [item[1] for item in top_trigrams]
labels.reverse()
counts.reverse()
plt.figure(figsize=(12, 10))
plt.barh(labels, counts, color='indigo')
plt.title(f'Top {N} Trigram Paling Sering Muncul')
plt.xlabel('Frekuensi')
plt.ylabel('Trigram')
for index, value in enumerate(counts):
plt.text(value, index, str(value))
plt.tight_layout()
plt.show()
Belum Maksimal
Saya mengakui bahwa analisis yang disajikan masih dapat dioptimalkan. Proses pembersihan data yang kurang maksimal, terutama dalam mengatasi bahasa gaul dan slang, berpotensi menghasilkan analisis yang bias. Untuk pengembangan selanjutnya, saya berencana menggunakan kemampuan pemrosesan bahasa dari Model Bahasa Skala Besar (seperti Gemini atau DeepSeek) untuk melakukan pembersihan dan standardisasi teks secara lebih efektif guna mengurangi risiko bias. Contoh analisis di atas berfungsi sebagai pengantar dasar untuk Analisis Sentimen.