
Terkait Dataset
Dataset yang digunakan dalam analisis ini adalah “Online Retail Sales Dataset”, seringkali dikenal sebagai file Online Retail.csv. Dataset ini merupakan kumpulan data poin yang ekstensif dan komprehensif terkait transaksi e-commerce. Dataset ini menyediakan pandangan mendetail mengenai aktivitas penjualan dalam sektor ritel online, mencakup berbagai atribut penting yang diperlukan untuk pemahaman kuantitatif perilaku konsumen dan kinerja bisnis secara keseluruhan.
Salah satu elemen kunci yang tercakup dalam dataset ini adalah InvoiceNo, yang merupakan pengidentifikasi unik untuk setiap transaksi yang terjadi. Karena keunikannya, kolom ini berfungsi sebagai kunci utama untuk membedakan transaksi individual. StockCode adalah atribut penting lainnya; setiap produk yang terdaftar atau dijual di platform ritel online ini memiliki kode identifikasi unik atau StockCode. Kode-kode ini membantu dalam klasifikasi item dan membedakan satu item dari lainnya.
Untuk pemahaman lebih lanjut, setiap produk dilengkapi dengan deskripsi dasar yang dicatat di bawah kolom Description. Dalam bentuk tekstual, deskripsi ini memberikan wawasan tentang apa sebenarnya setiap item produk tersebut. Selain membantu upaya identifikasi, deskripsi ini berpotensi membuka jalan untuk analisis berbasis teks.
Mengenai detail transaksi itu sendiri, kita memiliki dua kolom krusial: Quantity dan UnitPrice. Sesuai namanya, kolom ini masing-masing menunjukkan berapa banyak unit tertentu dari suatu item yang terjual per transaksi dan berapa harga per unit item tersebut saat dijual.
Informasi transaksi lebih lanjut dilengkapi dengan InvoiceDate, yang mencatat kapan setiap pembelian terpisah terjadi hingga catatan tanggal & waktu yang akurat. Data ini bisa menjadi sangat penting dalam mengenali pola penjualan sepanjang periode yang berbeda atau memprediksi tren masa depan berdasarkan perilaku waktu historis.
Terakhir, namun tidak kalah penting, adalah indikator global kita - kolom Country yang menentukan berbagai negara tempat tinggal pelanggan yang berinteraksi dengan platform online khusus ini secara teratur dengan melakukan pembelian. Kolom ini memungkinkan kita mendapatkan wawasan tentang dispersi geografis basis pengguna di berbagai negara, yang berpotensi memberikan kita wawasan tentang preferensi regional atau segmentasi pasar global.
Dengan kekayaan catatan transaksi terperinci dan informasi pelanggan seperti ini, dataset Online Retail.csv berdiri sebagai alat yang sangat berharga bagi mereka yang ingin mendalami analisis data penjualan ritel online. Kemungkinan dengan dataset ini sangat luas, mulai dari membentuk strategi pemasaran yang efisien berdasarkan data geografis hingga memprediksi metrik penjualan & pertumbuhan menggunakan perilaku historis dan banyak lagi.
Anda dapat menemukan dataset ini di: Kaggle: Online Retail Transaction Records.
Library
Untuk melakukan analisis keranjang belanja menggunakan algoritma Apriori, kita memerlukan beberapa pustaka Python. pandas akan digunakan untuk manipulasi dan pra-pemrosesan data, sementara mlxtend.frequent_patterns menyediakan implementasi dari algoritma Apriori dan fungsi untuk menghasilkan aturan asosiasi.
from mlxtend.frequent_patterns import apriori, association_rules
import pandas as pd
1. Pemuatan Data
Langkah pertama dalam analisis ini adalah memuat dataset Online Retail.csv ke dalam sebuah DataFrame pandas. DataFrame adalah struktur data tabular dua dimensi yang sangat fleksibel dan efisien untuk menangani data. Setelah memuat, kita akan menampilkan lima baris pertama data menggunakan df.head() untuk mendapatkan gambaran awal tentang struktur dan isi dataset.
Cuplikan kode
df = pd.read_csv("Online Retail.csv")
df.head()

Tahap 2: Pembersihan dan Pra-pemrosesan Data
Data mentah seringkali mengandung ketidaksempurnaan seperti nilai yang hilang, entri yang tidak valid, atau format yang tidak konsisten. Oleh karena itu, tahap pembersihan dan pra-pemrosesan sangat penting untuk memastikan kualitas data sebelum dilakukan analisis.
Langkah-langkah pembersihan yang dilakukan meliputi:
- Menghapus baris di mana
CustomerIDatauDescriptiontidak ada (dropna).CustomerIDpenting untuk mengidentifikasi transaksi unik pelanggan, danDescriptionpenting untuk mengidentifikasi item. - Mengkonversi kolom
InvoiceDatemenjadi tipe data datetime pandas (pd.to_datetime). Ini memungkinkan manipulasi dan analisis berbasis waktu jika diperlukan. - Menghapus transaksi yang merupakan pembatalan atau kredit. Transaksi ini biasanya ditandai dengan
InvoiceNoyang diawali huruf ‘C’. Kita hanya tertarik pada transaksi penjualan aktual. - Memastikan bahwa kuantitas (
Quantity) produk lebih besar dari nol. Kuantitas negatif bisa jadi menandakan barang retur. - Menghilangkan spasi ekstra di awal atau akhir
Descriptionproduk (str.strip()) dan memastikan deskripsi tidak kosong. Ini menjaga konsistensi nama item. - Mengkonversi
CustomerIDmenjadi tipe integer.
Setelah pembersihan, kita kembali menampilkan lima baris pertama dari DataFrame yang sudah dibersihkan.
df.dropna(subset=['CustomerID', 'Description'], inplace=True)
df['InvoiceDate'] = pd.to_datetime(df['InvoiceDate'])
df = df[~df['InvoiceNo'].astype(str).str.startswith('C')]
df = df[df['Quantity'] > 0]
df['Description'] = df['Description'].astype(str).str.strip()
df = df[df['Description'] != ''] # Hapus baris dengan deskripsi kosong setelah strip
df = df[df['Description'].str.lower() != 'nan'] # Hapus juga jika deskripsi adalah string 'nan'
df['CustomerID'] = df['CustomerID'].astype(int)
df.head()

Tahap 3: Transformasi Data untuk Apriori (Fokus pada Transaksi di UK)
Algoritma Apriori memerlukan data dalam format tertentu, yaitu matriks transaksi-item di mana setiap baris mewakili satu transaksi dan setiap kolom mewakili satu item. Nilai dalam matriks ini biasanya biner (1 jika item ada dalam transaksi, 0 jika tidak).
Untuk analisis ini, kita akan memfokuskan pada transaksi yang berasal dari ‘United Kingdom’ (UK). Ini dilakukan untuk mengurangi kompleksitas data dan karena mayoritas transaksi dalam dataset ini berasal dari UK, sehingga memberikan basis data yang cukup besar untuk analisis pola pembelian yang lebih homogen.
Langkah-langkah transformasi:
- Filter data untuk transaksi dari UK.
- Buat “keranjang belanja” (
basket_uk) dengan mengelompokkan data berdasarkanInvoiceNo(nomor faktur/transaksi) danDescription(nama item). Agregasisum()padaQuantitydigunakan, kemudianunstack()untuk mengubahDescriptionmenjadi kolom.fillna(0)mengisi item yang tidak ada dalam transaksi dengan nilai 0. - Konversi nilai dalam
basket_ukmenjadi biner: 1 jika kuantitas item > 0 (item dibeli), dan 0 jika tidak. - Hapus kolom ‘POSTAGE’ jika ada, karena ongkos kirim biasanya bukan item produk yang relevan untuk analisis asosiasi produk.
errors='ignore'digunakan agar kode tidak error jika kolom ‘POSTAGE’ tidak ada.
df_uk = df[df['Country'] == 'United Kingdom'].copy()
basket_uk = (
df_uk.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().fillna(0)
)
basket_uk = basket_uk.applymap(lambda x: 1 if x > 0 else 0)
basket_uk.drop(columns=['POSTAGE'], errors='ignore', inplace=True)
basket_uk.head()
Tahap 4: Penerapan Algoritma Apriori dan Pembuatan Aturan Asosiasi
Dengan data yang sudah dalam format yang benar, kita dapat menerapkan algoritma Apriori untuk menemukan frequent itemsets (kumpulan item yang sering muncul bersamaan dalam transaksi). Dari frequent itemsets ini, kita kemudian dapat menghasilkan aturan asosiasi.
Support (Dukungan): Ukuran seberapa sering suatu itemset muncul dalam dataset. Rumus Support untuk itemset X:
$$ Support(X) = \frac{\text{Jumlah transaksi yang mengandung } X}{\text{Total transaksi}} $$
Jika itemset terdiri dari dua item A dan B ($X = A \cup B$):
$$ Support(A \cup B) = \frac{\text{Jumlah transaksi yang mengandung } A \text{ dan } B}{\text{Total transaksi}} $$
Parameter min_support=0.02 berarti kita hanya tertarik pada itemset yang muncul di setidaknya 2% dari total transaksi di UK. use_colnames=True memastikan nama item digunakan dalam output, dan low_memory=True dapat membantu jika dataset sangat besar.
Setelah mendapatkan frequent itemsets, kita membuat aturan asosiasi. Aturan asosiasi biasanya berbentuk “Jika membeli item A, maka kemungkinan akan membeli item B” (A → B). Metrik yang umum digunakan untuk mengevaluasi aturan ini adalah:
Confidence (Kepercayaan): Ukuran seberapa sering item B dibeli ketika item A dibeli. Rumus Confidence untuk aturan A → B:
$$ Confidence(A \rightarrow B) = \frac{Support(A \cup B)}{Support(A)} = \frac{\text{Jumlah transaksi yang mengandung } A \text{ dan } B}{\text{Jumlah transaksi yang mengandung } A} $$
Lift: Ukuran seberapa besar kemungkinan item B dibeli ketika item A dibeli, dibandingkan dengan kemungkinan item B dibeli secara umum (tanpa memandang pembelian A). Rumus Lift untuk aturan A → B:
$$ Lift(A \rightarrow B) = \frac{Confidence(A \rightarrow B)}{Support(B)} = \frac{Support(A \cup B)}{Support(A) \times Support(B)} $$
Nilai lift > 1 menunjukkan bahwa A dan B memiliki asosiasi positif (pembelian A meningkatkan kemungkinan pembelian B). Lift = 1 berarti tidak ada asosiasi. Lift < 1 menunjukkan asosiasi negatif.
Kita akan mencari aturan dengan lift minimal 1.0 dan confidence minimal 0.2 (20%).
frequent_itemsets_uk = apriori(basket_uk, min_support=0.02, use_colnames=True, low_memory=True)
rules_uk = association_rules(frequent_itemsets_uk, metric="lift", min_threshold=1.0)
rules_uk = rules_uk[rules_uk['confidence'] >= 0.2] # Filter tambahan berdasarkan confidence
rules_uk.head()
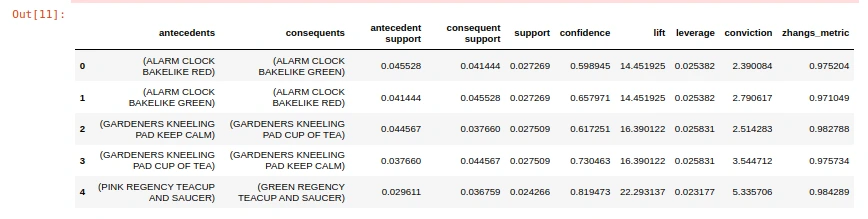
Wawasan dari Hasil (Interpretasi)
Setelah aturan asosiasi dihasilkan, kita perlu menginterpretasikannya untuk mendapatkan wawasan yang berguna. Kita akan menampilkan 5 aturan teratas yang diurutkan berdasarkan nilai lift tertinggi, kemudian confidence tertinggi. Untuk setiap aturan, kita akan menampilkan anteseden (item yang dibeli), konsekuen (item yang kemungkinan juga dibeli), serta nilai confidence, lift, dan support dari aturan tersebut.
Interpretasi:
- Antecedents: Item atau kumpulan item di sisi kiri aturan (“jika beli X”).
- Consequents: Item atau kumpulan item di sisi kanan aturan (“maka beli Y”).
- Support (aturan): Proporsi transaksi yang mengandung semua item dalam gabungan antecedents dan consequents.
- Confidence: Jika seseorang membeli item di antecedents, ada peluang sebesar X% (nilai confidence) mereka juga akan membeli item di consequents.
- Lift: Seberapa kali lebih mungkin seseorang membeli item di consequents jika mereka telah membeli item di antecedents, dibandingkan jika mereka membeli item di consequents tanpa informasi pembelian item di antecedents. Lift > 1 adalah yang paling menarik.
Cuplikan kode
for _, row in rules_uk.sort_values(by=['lift', 'confidence'], ascending=[False, False]).head(5).iterrows():
A = ', '.join(list(row['antecedents'])) # Konversi frozenset ke list lalu join
B = ', '.join(list(row['consequents'])) # Konversi frozenset ke list lalu join
print(f"\nJika beli {{{A}}} → kemungkinan {row['confidence']:.2%} beli {{{B}}} (lift: {row['lift']:.2f}, support: {row['support']:.2%})")

Sistem Rekomendasi Sederhana
Aturan asosiasi yang telah kita temukan dapat digunakan untuk membangun sistem rekomendasi produk sederhana. Fungsi get_recommendations berikut mengambil nama satu item sebagai input dan, berdasarkan aturan yang telah dibuat, merekomendasikan item lain yang mungkin diminati pelanggan.
Logika fungsi:
- Memfilter aturan di mana item input (
item_name) adalah bagian dari anteseden. - Mengumpulkan semua item konsekuen dari aturan-aturan yang relevan.
- Menghindari merekomendasikan item input itu sendiri.
- Mengurutkan item-item yang direkomendasikan berdasarkan
lift,confidence, dansupport(dalam urutan menurun) untuk menampilkan rekomendasi yang paling kuat terlebih dahulu. - Menghapus duplikat rekomendasi dan mengembalikan
top_nitem teratas.
Fungsi ini melakukan pemeriksaan dasar untuk memastikan DataFrame aturan (rules_df) tidak kosong dan memiliki kolom yang diperlukan sebelum mencoba menghasilkan rekomendasi.
def get_recommendations(item_name, rules_df, top_n=5):
required_columns = ['antecedents', 'consequents', 'lift', 'confidence', 'support']
if rules_df.empty or not all(col in rules_df.columns for col in required_columns):
print("DataFrame aturan kosong atau tidak memiliki kolom yang dibutuhkan.")
return []
relevant_rules = rules_df[rules_df['antecedents'] == frozenset({item_name})]
if relevant_rules.empty:
return []
all_consequents_data = []
for _, rule in relevant_rules.iterrows():
for an_item_in_consequent_set in rule['consequents']:
if an_item_in_consequent_set != item_name:
all_consequents_data.append({
'item': an_item_in_consequent_set,
'lift': rule['lift'],
'confidence': rule['confidence'],
'support': rule['support']
})
if not all_consequents_data:
return []
recommendations_df = pd.DataFrame(all_consequents_data)
recommendations_df = recommendations_df.sort_values(
by=['lift', 'confidence', 'support'],
ascending=[False, False, False]
)
# Ambil item unik dan pilih top_n
unique_recommendations = recommendations_df.drop_duplicates(subset=['item'])
top_recommendations_list = unique_recommendations['item'].head(top_n).tolist()
return top_recommendations_list
Kita kemudian dapat menggunakan fungsi ini untuk mendapatkan rekomendasi untuk item tertentu. Sebagai contoh, kita akan mencari rekomendasi untuk item “JUMBO BAG RED RETROSPOT”.
item_dibeli = "JUMBO BAG RED RETROSPOT"
# Pastikan rules_uk sudah ada dan tidak kosong
if 'rules_uk' in locals() and isinstance(rules_uk, pd.DataFrame) and not rules_uk.empty:
print(f"Mencari rekomendasi untuk: '{item_dibeli}'")
rekomendasi_item = get_recommendations(item_dibeli, rules_uk, top_n=5)
if rekomendasi_item:
print(f"\nKetika Anda membeli '{item_dibeli}', Anda mungkin juga tertarik untuk membeli:")
for i, rec in enumerate(rekomendasi_item):
print(f"{i+1}. {rec}")
else:
print(f"\nTidak ada rekomendasi ditemukan untuk '{item_dibeli}' berdasarkan aturan yang ada.")
else:
print(f"\nAturan asosiasi ('rules_uk') tidak tersedia atau kosong. Tidak dapat memberikan rekomendasi untuk '{item_dibeli}'.")
