
Saat mengunjungi toko buku, pasti Anda pernah melihat buku yang sampul plastiknya telah dibuka oleh pengunjung tetapi tidak dibeli. Ini menjadi kesempatan untuk membaca buku tersebut.
Saya membaca novel karya Keigo Higashino dengan judul The Devotion Of Suspect X, saya menyukai buku-bukunya karena ditulis dengan rapi serta memahami sifat psikologi manusia dengan mendalam.
Saat membaca, saya sedikit terganggu oleh lagu viral yang diputar di ruangan itu. Ketika mencoba membaca dalam hati, lirik lagu tersebut seolah ingin mengambil alih, membuat saya sulit berkonsentrasi pada novel.
Orang yang mengendalikan pengeras suara itu tampaknya tidak tahu bahwa musik instrumental lebih baik daripada lagu berlirik untuk menemani kegiatan membaca.

E. Colin Cherry From Mathshistory.st-andrews.ac.uk
Karena sulit berkonsentrasi, akhirnya saya mencoba membaca dengan bersuara, meskipun mungkin tidak begitu jelas bagi orang lain karena berbaur dengan suara musik yang diputar. Namun, saya masih bisa mendengar suara bacaan saya sendiri.
Saat melakukannya, saya merasa lebih bisa fokus karena mendengar suara sendiri, walaupun volume musik lebih keras daripada suara saya.
Manusia memiliki fokus auditori yang luar biasa. Bayangkan Anda berada di tengah perdebatan sengit antara dua tetangga: sebut saja A, yang anjingnya kedapatan buang kotoran di halaman tetangga B. Akibatnya, terjadilah adu argumen di antara keduanya, masing-masing saling melontarkan pendapat tanpa memberi kesempatan satu sama lain untuk berbicara.
Dalam situasi tersebut, jika Anda memfokuskan diri untuk mendengar tetangga A Anda seperti membenamkan telinga untuk tetangga B begitu juga sebaliknya. Meskipun harus membutuhkan konsentrasi ekstra untuk melakukannya. Untuk lebih memahami ilustrasinya mari lihat video berikut ini
Cocktail Party Effect By Mark_Mitton from Youtube.com
Cocktail Party Effect

E. Colin Cherry From Mathshistory.st-andrews.ac.uk
Pada tahun 1953, E. Colin Cherry menerbitkan artikel berjudul Some Experiments on the Recognition of Speech, with One and with Two Ears. Dalam artikel tersebut, Cherry melakukan serangkaian tujuh eksperimen untuk menyelidiki bagaimana manusia dapat memusatkan perhatian pada satu sumber suara meski terdapat gangguan dari sumber suara lain—kemampuan yang dikenal sebagai cocktail party effect. Berikut akan dibahas tiga eksperimen dari penelitian ini; rincian mengenai eksperimen lainnya dapat ditemukan dalam artikel asli Cherry di bagain referensi.
1. Mendengarkan Selektif: Memisahkan Suara dalam Keramaian

E. Colin Cherry From Mathshistory.st-andrews.ac.uk
Dalam eksperimen ini, para peneliti mencoba memahami bagaimana kita bisa fokus pada satu percakapan ketika ada banyak suara lain di sekitar, sebuah fenomena yang dikenal sebagai “Cocktail Party Effect”. Caranya, dua pesan berbeda yang diucapkan oleh orang yang sama direkam menjadi satu pada pita magnetik. Subjek (pendengar) kemudian diminta untuk mendengarkan rekaman tersebut dan mencoba mengulangi salah satu dari dua pesan itu, kata demi kata atau frasa demi frasa. Mereka diberi kebebasan untuk memutar rekaman itu sebanyak yang mereka perlukan untuk menyelesaikan tugas.
Hasilnya menunjukkan bahwa meskipun rekaman itu terdengar seperti “babel” atau suara campur aduk, subjek ternyata mampu memisahkan salah satu pesan yang ingin mereka dengarkan. Mereka berhasil mengenali frasa-frasa dari pesan yang dipilih, walaupun kadang membuat kesalahan kecil yang umumnya masuk akal berdasarkan konteks kalimatnya. Subjek melaporkan bahwa tugas ini sangat sulit dan membutuhkan konsentrasi tinggi, bahkan ada yang sampai memutar ulang beberapa frasa 10 hingga 20 kali sebelum akhirnya berhasil menebak dengan benar. Ini membuktikan bahwa kita memiliki kemampuan untuk menyaring dan fokus pada informasi suara tertentu di tengah gangguan.
2. Fokus Satu Telinga: Mengabaikan Pesan yang Tidak Diinginkan

E. Colin Cherry From Mathshistory.st-andrews.ac.uk
Eksperimen ini menyelidiki apa yang terjadi ketika dua pesan berbeda disajikan secara terpisah ke masing-masing telinga pendengar. Satu pesan ucapan yang berkelanjutan diperdengarkan melalui headphone ke telinga kiri subjek, sementara pesan yang berbeda, meskipun dari pembicara yang sama, diperdengarkan ke telinga kanan. Subjek kemudian diinstruksikan untuk memilih salah satu pesan (misalnya, yang di telinga kanan) dan mengulanginya secara langsung kata demi kata sambil terus mendengarkan, dan berusaha untuk tidak membuat kesalahan.
Hasilnya sangat menarik. Subjek tidak mengalami kesulitan sama sekali untuk fokus pada pesan di satu telinga dan secara efektif “mengabaikan” atau “menolak” pesan di telinga lainnya. Mereka bisa mengulangi pesan yang mereka pilih dengan lancar, meskipun suara mereka cenderung menjadi datar dan monoton, dan seringkali mereka tidak begitu memahami makna dari apa yang baru saja mereka ulangi. Namun, poin yang paling signifikan adalah ketika ditanya mengenai isi pesan di telinga yang mereka “tolak”, subjek mengaku hampir tidak tahu apa-apa tentangnya, paling-paling mereka hanya sadar bahwa ada suara di sana. Ini menunjukkan betapa kuatnya kemampuan kita untuk mengarahkan fokus pendengaran dan mengabaikan informasi lain.
3. Jejak Samar Pesan Terabaikan: Apa yang Masih Terdengar?

E. Colin Cherry From Mathshistory.st-andrews.ac.uk
Setelah mengetahui bahwa pesan di telinga yang “ditolak” sebagian besar tidak disadari, penelitian ini bertujuan untuk mencari tahu apakah ada aspek tertentu dari pesan yang terabaikan tersebut yang masih bisa dikenali oleh pendengar. Subjek diminta untuk fokus mendengarkan dan mengulangi pesan yang diperdengarkan di telinga kanan mereka. Sementara itu, berbagai jenis sinyal suara dimasukkan ke telinga kiri mereka (sebagai pesan yang “ditolak”), seperti ucapan normal oleh pria, ucapan oleh wanita, ucapan pria yang diputar terbalik (sehingga tidak bermakna), atau hanya nada suara murni 400-cps. Setelah selesai, subjek diberi pertanyaan mengenai apa yang mereka dengar di telinga kiri yang “ditolak” itu.
Hasilnya menunjukkan bahwa meskipun pendengar tidak mengingat isi atau bahkan bahasa pesan yang ditolak (misalnya, apakah itu Bahasa Inggris atau bukan), mereka masih bisa menangkap beberapa karakteristik fisik atau statistik dari suara tersebut. Misalnya, mereka hampir selalu bisa mengidentifikasi jika suara di telinga yang ditolak itu adalah suara manusia atau bukan, dan mereka juga bisa mengenali perubahan suara dari pria ke wanita. Nada suara murni juga selalu terdeteksi. Ini berarti, walaupun kita tidak memproses makna dari pesan yang kita abaikan, otak kita tampaknya masih melakukan analisis dasar terhadap sifat-sifat fisik suara tersebut.
Kesimpulan
Penelitian ini menyimpulkan bahwa manusia memiliki kemampuan luar biasa untuk mengenali dan memisahkan ucapan dalam kondisi yang kompleks, yang tampaknya bergantung pada mekanisme internal untuk menilai probabilitas linguistik dan kemampuan untuk secara selektif mengarahkan perhatian pendengaran. Eksperimen menunjukkan bahwa pendengar dapat menyaring satu pesan dari dua yang tumpang tindih, bahkan dari pembicara yang sama, meskipun pesan yang sangat probabilistik seperti rangkaian klise dapat mengacaukan kemampuan ini.
Speech Transmission Index (STI)
Kita beralih ke penelitian lanjutan mengenai Speech Transmission Index (STI) sebagai pengembangan dari fenomena Cocktail Party Effect. Penelitian sebelumnya memang berhasil menunjukkan adanya pengaruh kebisingan terhadap kemampuan memahami ujaran, namun tetap memerlukan fokus ekstra dari subjek yang diuji. Oleh karena itu, fokus pembahasan kita berlanjut ke tingkat pemahaman kalimat di tengah kebisingan, dengan mempertimbangkan faktor usia, jenis kelamin serta kuatnya(dalam desibel) suara kebisingan itu.
Acoustic phenomena - Speech intelligibility By EcophonTV from Youtube.com
Pada tahun 1979, R Plomp & A M Mimpen melakukan penelitian yang melibatkan 140 pria dan 72 wanita dari berbagai kelompok usia. Pria dibagi rata ke dalam setiap dekade usia antara 20 hingga 89 tahun, sementara wanita terdiri dari 20 orang per dekade usia antara 60 hingga 89 tahun, serta 12 orang berusia 90–96 tahun. Pria berusia 20–64 tahun direkrut secara acak dari karyawan di perusahaan teknik, sedangkan pria di atas 64 tahun dan wanita di atas 60 tahun sebagian besar tinggal di panti jompo. Hanya sedikit pria yang pernah bekerja di lingkungan dengan kebisingan tinggi, dan peserta lansia yang mengalami gangguan mental parah dikecualikan dari penelitian.
Jenis Kehilangan Pendengaran dalam Ujaran (SHL – Speech Hearing Loss)
Penelitian ini mengidentifikasi dua jenis utama gangguan pendengaran saat mendengar ujaran:
🔈 SHL Kelas A (Atenuasi)
Kehilangan pendengaran karena suara menjadi lebih lemah atau redup.
Umumnya terjadi karena penurunan sensitivitas telinga terhadap suara.
🔊 SHL Kelas D (Distorsi)
Kehilangan pendengaran karena suara yang masuk menjadi terdistorsi (tidak jelas atau kacau).
Lebih terasa dalam kondisi bising.
➕ SHL A+D (Gabungan Atenuasi dan Distorsi)
Menggambarkan tingkat gangguan pendengaran dalam kondisi tenang.
Semakin tinggi nilainya, semakin besar kesulitan seseorang memahami ujaran meskipun tidak ada gangguan suara di sekitar.
📢 SHL D (Distorsi saja)
- Digunakan untuk mengukur kehilangan pendengaran dalam lingkungan bising.
Perkembangan Seiring Usia
E. Colin Cherry From Mathshistory.st-andrews.ac.uk
🧓 Setelah usia 50 tahun, baik SHL A+D maupun SHL D cenderung meningkat secara bertahap.
Pada usia 85 tahun, nilai rata-rata:
SHL A+D: 30 dB 📉 (kesulitan mendengar dalam kondisi tenang)
SHL D: 6 dB 🔇 (kesulitan tambahan saat suasana bising)
Jadi dapat disimpulkan jika :
Orang yang lebih tua mengalami kesulitan mendengar bahkan dalam suasana tenang, dan tantangan ini menjadi lebih berat saat berada di tempat yang bising.
Jika Anda ingin, saya juga bisa bantu visualisasi data ini dalam bentuk grafik sederhana atau diagram.
👂📉 Penurunan Kemampuan Mendengar pada Lansia
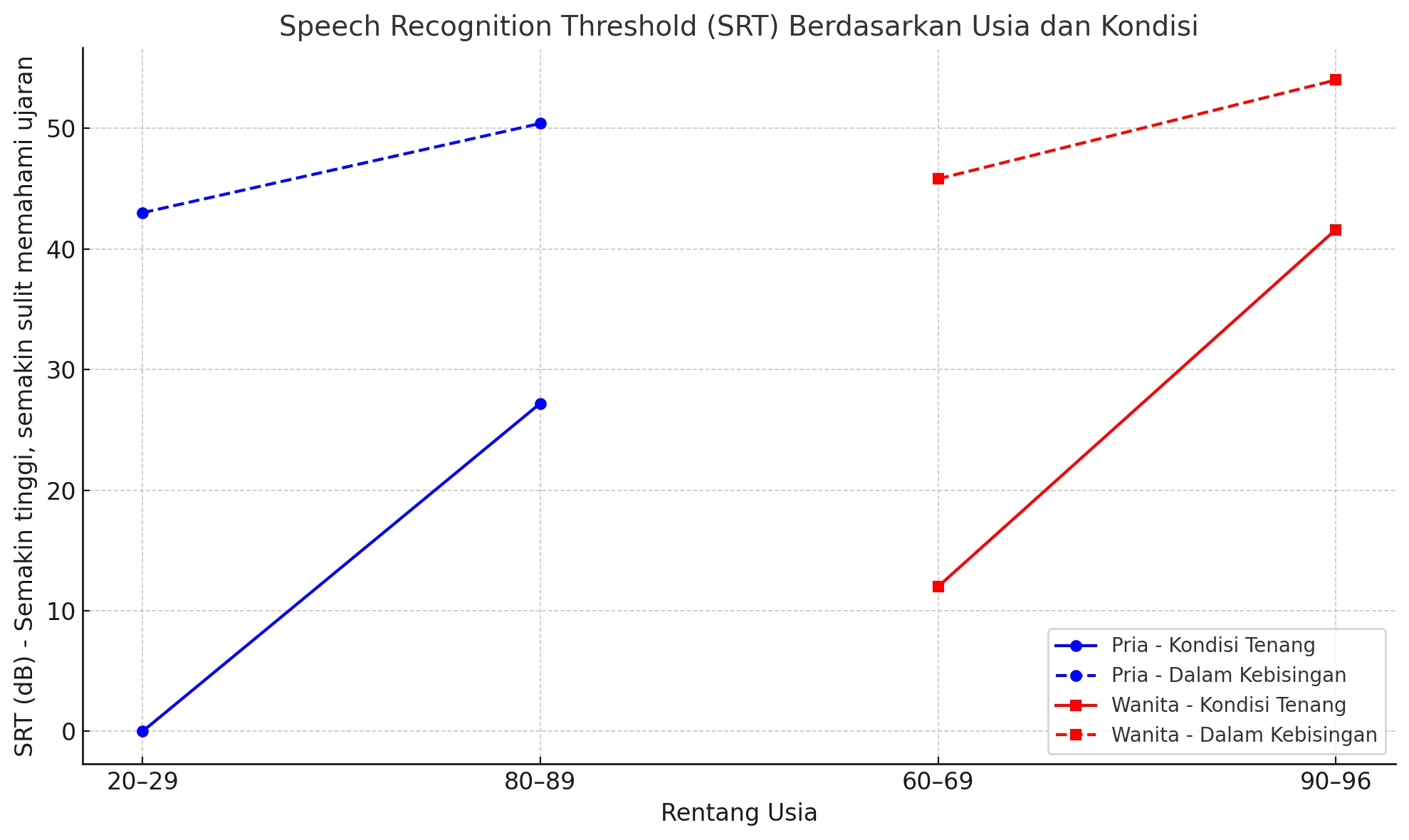
Penelitian ini menunjukkan bahwa ambang pengenalan ujaran (SRT - Speech Recognition Threshold) meningkat seiring bertambahnya usia, baik pada pria maupun wanita. Semakin tinggi angka SRT, semakin keras suara yang dibutuhkan agar bisa dipahami.
👨🦳 Untuk Pria:
🔇 Kondisi Tenang:
- Usia 20–29 tahun: 0 dB (pendengaran sangat baik)
- Usia 80–89 tahun: 27,2 dB (butuh suara lebih keras)
🔊 Dalam Kebisingan (67,5 dBA):
- Usia 20–29 tahun: 43,0 dB
- Usia 80–89 tahun: 50,4 dB
📌 Artinya: Pria lanjut usia membutuhkan suara yang jauh lebih keras untuk memahami ujaran, apalagi jika suasananya bising.
👵 Untuk Wanita:
🔇 Kondisi Tenang:
- Usia 60–69 tahun: 12,0 dB
- Usia 90–96 tahun: 41,6 dB
🔊 Dalam Kebisingan (67,5 dBA):
- Usia 60–69 tahun: 45,8 dB
- Usia 90–96 tahun: 54,0 dB
Artinya: Wanita lansia juga mengalami penurunan kemampuan mendengar, terutama saat berada di lingkungan ramai atau bising.
🧠 Kesimpulan :
- 📈 Kemampuan memahami ujaran menurun secara signifikan seiring usia.
- 📢 Kebisingan memperburuk kemampuan ini, baik pada pria maupun wanita.
- 🧓Penemuan ini mengingatkan kita untuk memperhatikan kondisi pendengaran lansia, terutama saat mereka berada di lingkungan sosial atau tempat umum yang bising.
- 💬 Dengan begitu, kita bisa meningkatkan kualitas komunikasi dan kesejahteraan mereka dalam kehidupan sehari-hari.
Rekomendasi
Bagi pemilik tempat seperti kafe, restoran, toko buku, atau bahkan kreator konten, di mana fokus utama pengunjung bukanlah musik itu sendiri, sangat penting untuk mempertimbangkan tingkat desibel (dB) dari musik latar yang diputar. Penelitian oleh Plomp & Mimpen (1979) menunjukkan bahwa kebisingan latar dapat secara signifikan mengganggu kemampuan seseorang untuk memahami percakapan, terutama bagi individu lanjut usia yang membutuhkan lingkungan lebih tenang untuk berkomunikasi secara efektif.
Dengan menurunkan volume musik latar—idealnya 5 hingga 10 dB lebih rendah dari standar umum jika audiens Anda mencakup lansia —Anda tidak hanya mengurangi ‘rasa bising’, tetapi juga menciptakan suasana yang lebih inklusif. Ini memungkinkan pengunjung, khususnya mereka yang lebih tua atau memiliki sensitivitas pendengaran, untuk menikmati suasana, berinteraksi dengan nyaman, dan memahami percakapan tanpa kesulitan.
Meskipun musik latar dapat berkontribusi pada ketenangan emosional, manfaat ini akan lebih optimal jika tidak mengorbankan kemudahan berkomunikasi dan kenyamanan pendengaran semua pengunjung.
Referensi
E. Colin Cherry (1953). Some Experiments on the Recognition of Speech, with One and with Two Ears. Journal of Personality and Social Psychology, 25(5), 975–979. PDF Journal
R Plomp, A M Mimpen (1979). Speech-reception threshold for sentences as a function of age and noise level. J Acoust Soc Am. 66(5), 1333-42. PDF Journal